The Marketer’s Guide to Identifying & Fixing Google Index Bloat
Google has rolled out a number of quality related updates recently – from Panda to Fred to Phantom, it’s clear that quality content and strong user engagement metrics are increasingly important components of ranking well in Google.
While you may not need to recover from an explicit Google penalty, if a lot of your web pages are getting indexed, there’s a good chance that your site may be suffering because of low-quality, duplicated content that is eating up crawl budget and link equity, while also having very poor link and engagement metrics.
Index bloat is when your website has too many redundant pages in the search engine index. Share on XSo how can you – as a marketer who may not have a comprehensive understanding of how Google’s index works – find and fix indexation issues?
In this post I’ll walk you through some relatively simple (but frequently time-consuming) steps for identifying if you have an issue with duplicate/thin content and indexation, how to determine which pages are causing the problem, and your options for cleaning it up.
Learn More: How to Recover From Any Google Penalty
TABLE OF CONTENTS:
Step 1: Determine if You’re Suffering from “Index Bloat”
The first step here is to identify whether you have an issue at all. What we’re looking to discern out of the gate are the number of pages you’re allowing to be indexed versus the number of pages that actually rank and drive traffic.
First, we can get some rough estimates as to how many pages on our site are indexed by going to Google and doing a site operator for our domain. My kids and I watched Harry Potter last night, so I’ll use the Pottermore.com site as an example here:
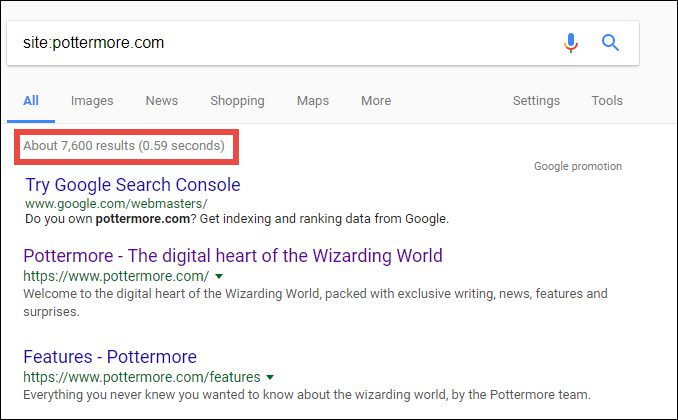
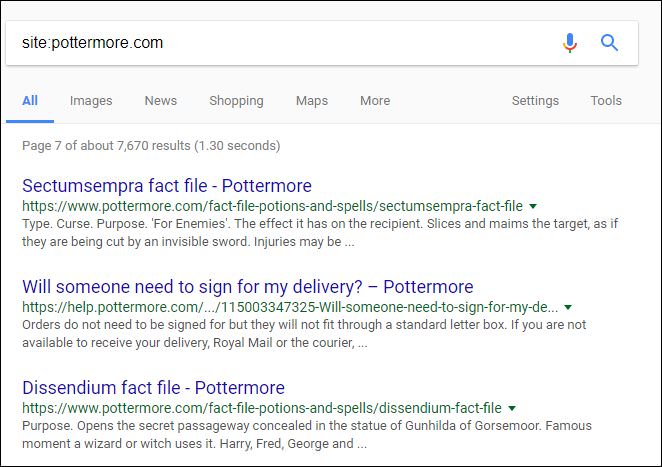
The site search operator can be a bit confusing – if I actually click through all the results for Pottermore.com, I only see a few hundred results (I’m showing 100 results per page, so I click through to the last page of results, click show all, and now we are seeing the first few results from 601-700):
Google’s Gary Illyes explained that these are just estimates, and are less accurate for larger sites:
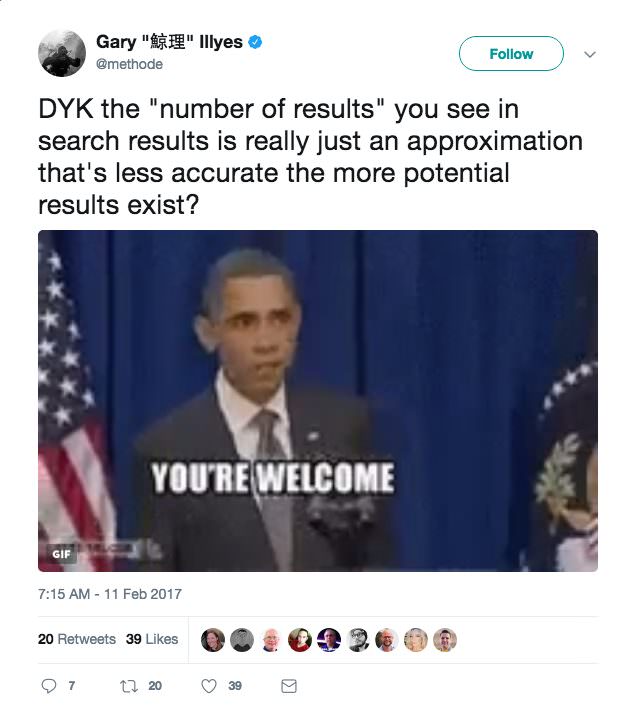
This is one of the things that makes diagnosing indexation issues difficult: there’s not always a comprehensive, specific list of the exact pages that are or aren’t in the index, and there are frequently many pages on your site that are indexed that you aren’t seeing in search results.
I’ll go into more detail on how to deal with that knowledge gap in a minute, but beyond the site operator estimates you can also get indexation numbers from Google Search Console:
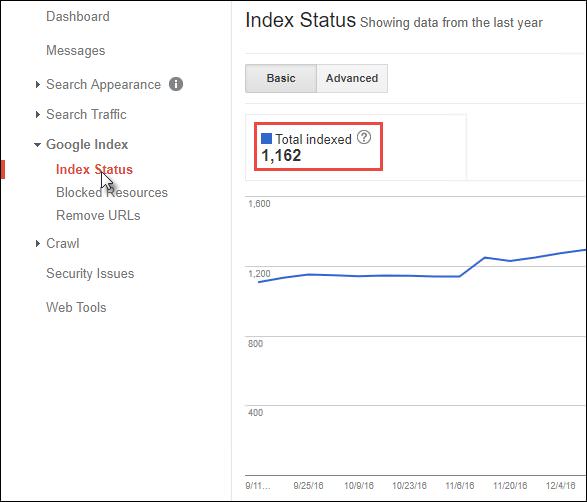
Obviously we don’t have access to Pottermore’s Google Search Console account (the above is an example from a different site), but if we did we could check the raw indexation numbers against the estimate (for smaller sites, frequently you’ll find they match up fairly closely).
Once you’ve quickly checked to see how many of your site’s pages are in the index, you’ll want to understand, at a high level, how many actually drive organic traffic for your site. To do this, you can start with Google Analytics:
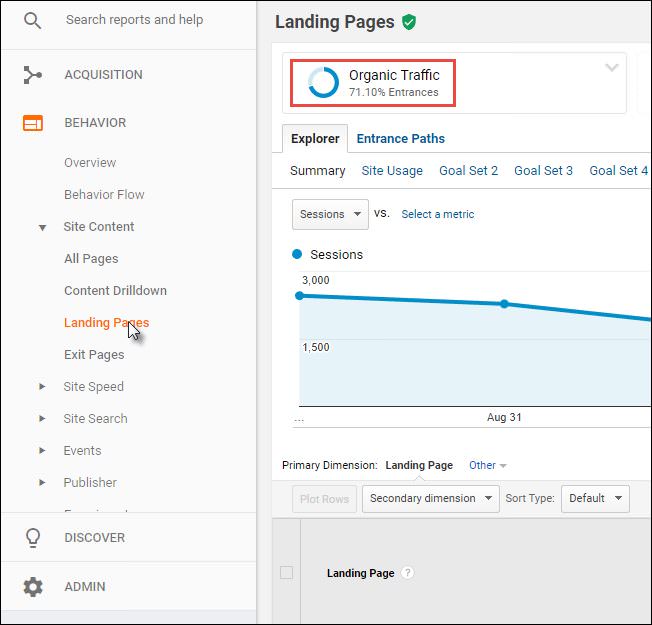
I always like to create a custom report to see landing page data, but you can also quickly drill down to your content report and look at the organic traffic segment as pictured above, and scroll to the bottom of the screen to see the number of pages actually driving traffic:

Similarly, you can see the number of pages generating search impressions within Google Search Console by looking at Search Analytics and drilling down to clicks (or impressions) and pages:
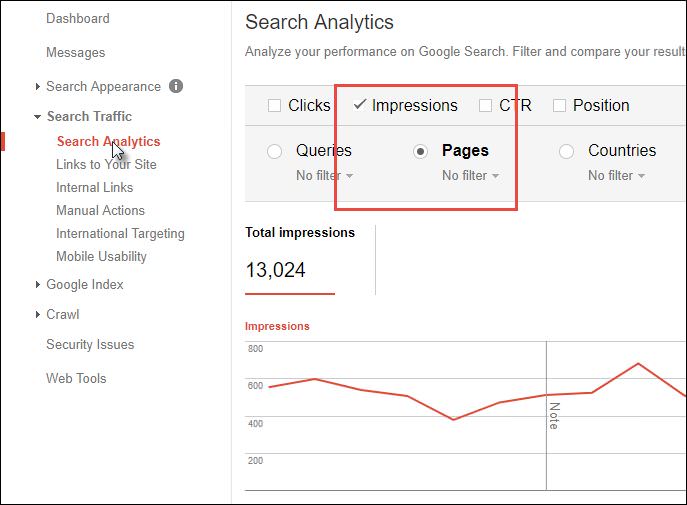
And then looking at the total number of pages listed:

If you have thousands of pages showing in the index in Google Search Console and in site search operator estimates, but only a few hundred pages drive all your site’s traffic (and/or only a handful of pages drive most of your site’s traffic), you likely have an issue.
Learn More: 10 Google Search Console Hacks to Boost SEO
Step 2: Diagnosing Which Pages Are Causing Your Indexation Issues
So you’ve looked at the rough number of indexed pages for your site and the pages actually driving traffic to your site, and have identified a potential issue: how do you go about actually identifying which pages on your site present an “indexation issue?”
In other words: how do you know what pages you should be “cleaning up” and getting out of the index?
There are a few great tools that can help with this process.
Deep Crawl
I use Deep Crawl frequently, particularly for larger sites. It may be a bit pricey for some, but if you’re making an investment in SEO and have indexation issues it’s pretty easy to justify a subscription (if the price tag is a turn-off, don’t worry, I’ll outline some less expensive options as well).
Essentially what you can do here is start a crawl, and be sure to link Google Search Console accounts for your site. Once you’ve run a crawl, which can take some time, you’ll be able to get access to all kinds of great data, but for our purposes we want to start by going to Issues > Duplicate Content:
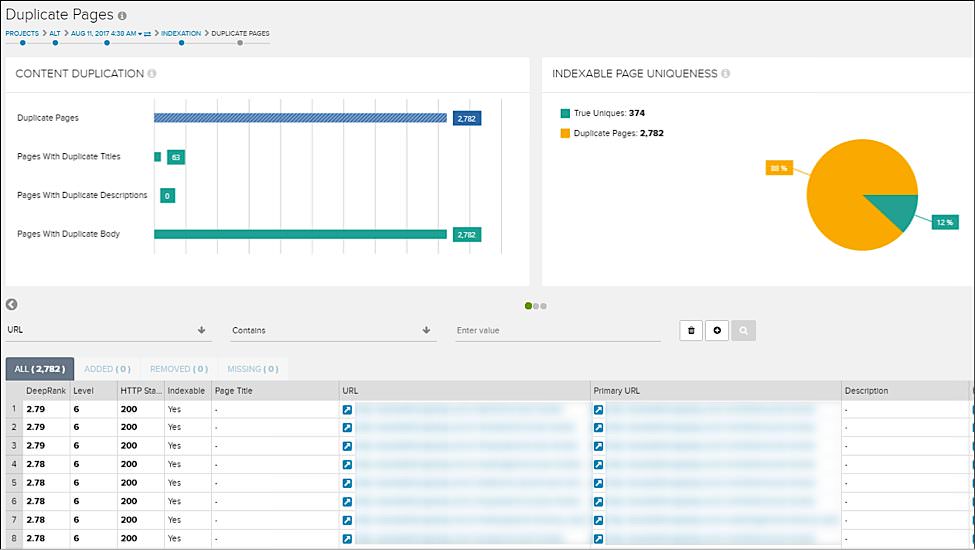
As you can see, you can quickly get a sense of the pages on your site that are indexable and duplicated.
Next, however, comes the hard part: analyzing these URLs to find out why your content is duplicated (and then actually fixing the issues!). We’ll deal more with that in step three.
For now, we want to look at one other Deep Crawl report called Indexable Pages without Search Impressions:
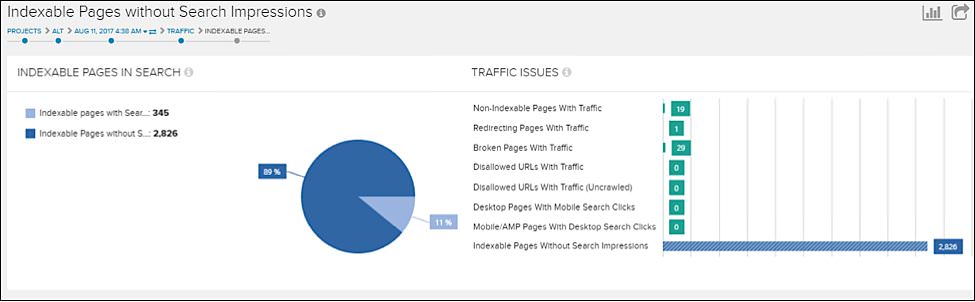
If we navigate to Traffic > Landing Pages > Indexable Pages Without Search Impressions we get the above report.
In the case of this particular site, most of the duplicated pages actually aren’t getting any search impressions, but for many sites the “Indexable Pages without Search Impressions” may include a lot of pages that don’t show up as pure “duplicates” but are actually unique pages, just lower quality. (Again: more on how to sift through these and determine what to remove from the index later.)
Screaming Frog
Screaming Frog is another great (and less expensive) option for identifying duplicate content and areas of your site where pages are indexable but not showing up in search results. Once you’ve run a crawl of your site, you can quickly get a list of pages with duplicated title tags or meta descriptions:
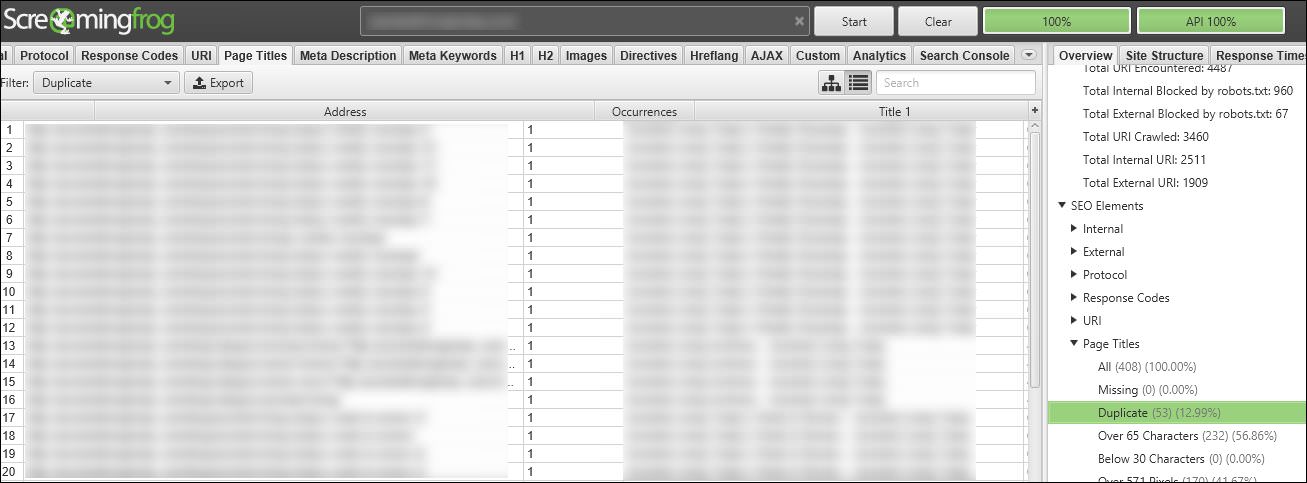
Once again, after you’ve linked your Google Search Console account you can generate a report with all the URLs that did get crawled, are indexable, and aren’t showing up in Google Search Console:
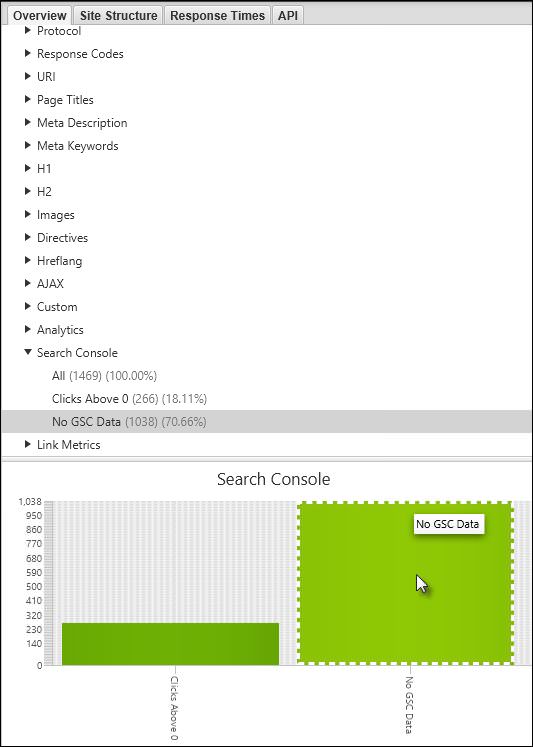
Google Search Console
A third and even better-priced (i.e. free!) option for getting to helpful duplicate content and indexation information is Google Search Console. With this tool you can quickly drill down to get duplicated title tag and meta description information as you would with Screaming Frog or Deep Crawl:
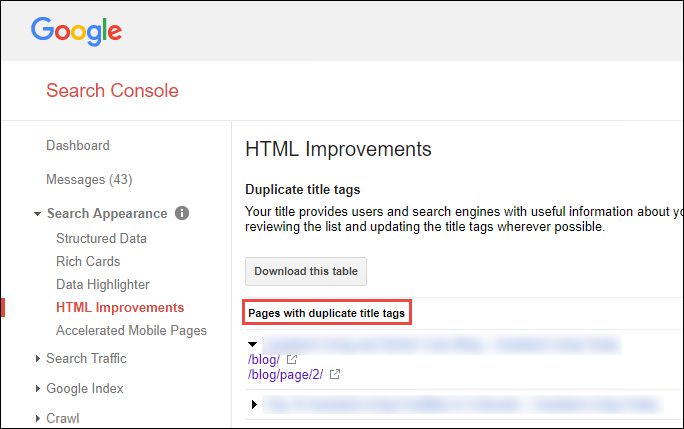
One advantage of the Search Console data is that you’re actually getting the report “straight from the horse’s mouth” and can get a glimpse into what Google actually sees.
Beyond this duplicated data, Google also has a new “Index Status” report (currently in beta and being rolled out to more accounts) which offers a lot more data on which specific pages on your site are actually being indexed:
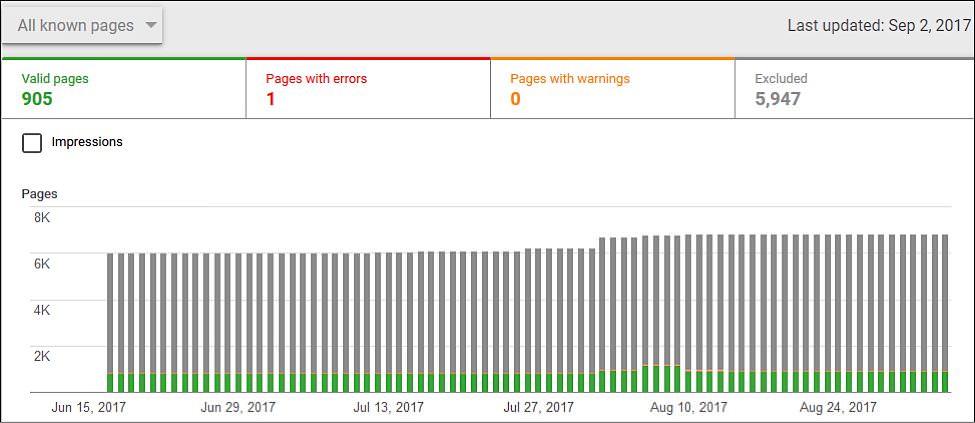
The report even allows you to drill down to see specific issues with pages and “indexed, low interest” pages where Google has indexed the page, but doesn’t crawl it often:
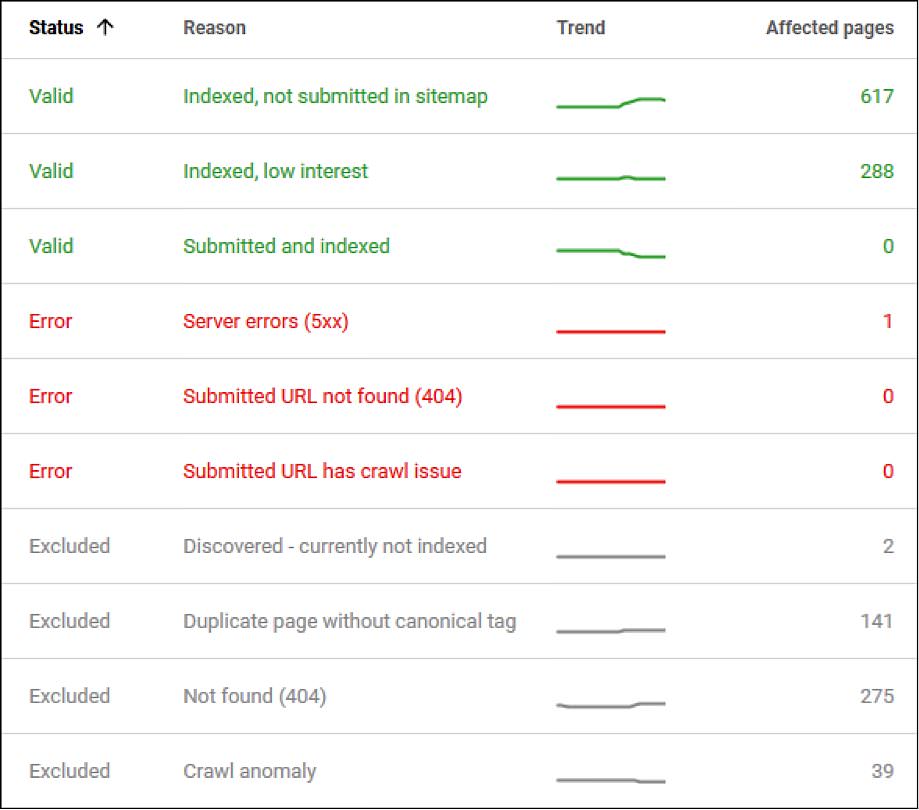
These indexed, low-interest pages may be pages you want indexed (so you don’t noindex or delete them automatically), but they very well may also be lower-quality pages you can work on removing from the index.
Google Analytics
Now that you’ve worked through Deep Crawl, Screaming Frog, and/or Google Search Console, you’re likely aware of a lot of duplicated pages and indexed pages that you don’t want indexed.
The next step will be to work on actually removing these pages from the index, but first we want to make sure that we don’t skip over one remaining cohort of pages that we might want to remove from the index: low-quality pages with poor engagement.
As you saw, the reports above largely focus on duplicated content and pages that are indexable but get no impressions or traffic. But what about the pages on your site that may be “legitimate” pages yet have no real value to visitors?
If you have a batch of three-year-old press releases or a subsection of your site that’s been neglected and isn’t relevant or useful, there may still be some traffic from search going to those pages, but visitors might not be having a positive experience when they get there.
To unearth pages with relatively few visits and poor engagement signals, we can drill down to look at a landing page report in Google Analytics segmented for organic traffic:
If you grab a significant amount of data in terms of date-range (e.g. the previous year), you can then export that report and see which pages have unusually high bounce rates:
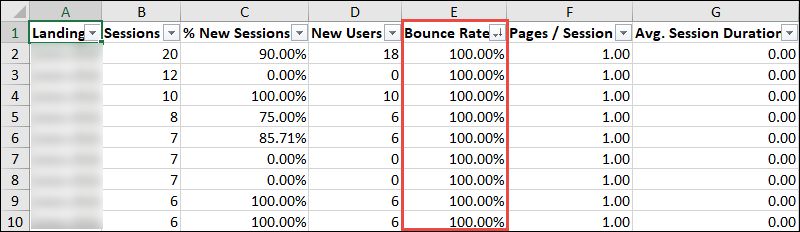
In this report there were a handful of these types of pages, which I find is often the case, even with relatively simple sites that have just been creating blog content consistently for an extended period.
So now you should have a big list of URLs that are some combination of:
- Duplicated content
- Pages that are indexed but not generating any impressions
- Pages that have very poor engagement metrics (high bounce rates, low time on site, etc.)
Next comes the trickiest part: actually removing these pages from the index and fixing your issues with “index bloat.”
Related Content: How to Set Up Goals and Funnels in Google Analytics
Step 3: Removing Low-Quality Pages & Fixing Your Indexation Issues
As you move to actually sorting out your indexation issues, the first step is figuring out which types of duplicate and low-quality content are present in the index. You should have a big list of URLs that are likely duplicated or low value as a result of the first two steps, but how do you actually address these issues?
I like to start by classifying the different types of issues that the site is suffering from. This is something that can be quite time consuming since you have to review each of the URLs you’re seeing in these reports. If you’ve reviewed a lot of different sites, then this is something you get pretty adept at and can frequently identify pretty quickly, but assuming you’re new to indexation issues, here’s how you can start to dig in.
First, you want to make sure that the page in question is actually a duplicate or thin page you’re considering eliminating. Then you need to look for the root of the issue you’re seeing. Why is this page thin or duplicated? In most instances, the reason a URL is duplicated will be something that’s repeated across a variety of different pages.
Let’s dig into some reports for Pottermore to see examples.
In looking at the Screaming Frog duplicate title tag report, we see some pages that have the same title tags:
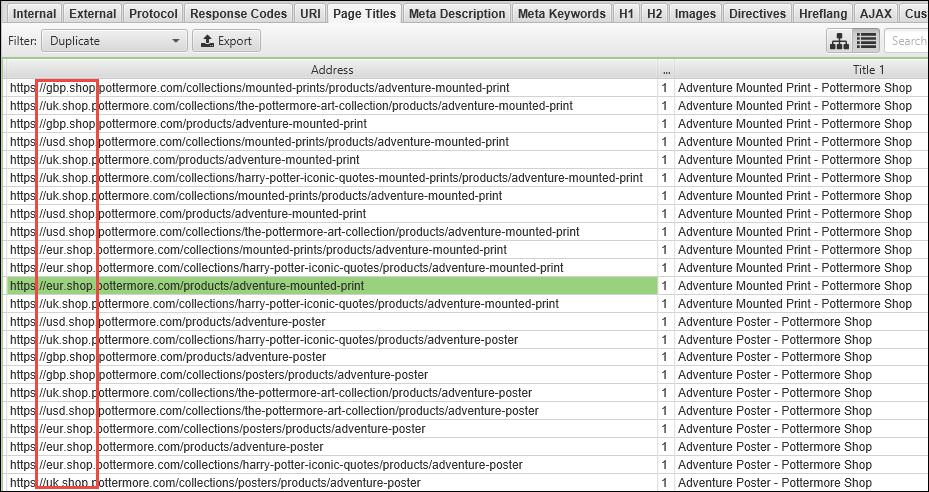
This is effectively the same content on different URLs and subdomains. In this instance, however, the site is configured to deliver different shopping pages based on geography. While that may be the best experience for the user, there are no hreflang tags applied to these pages to help Google understand their purpose.
Here we can see that two distinct geo-targeted versions of the same page are indexed:
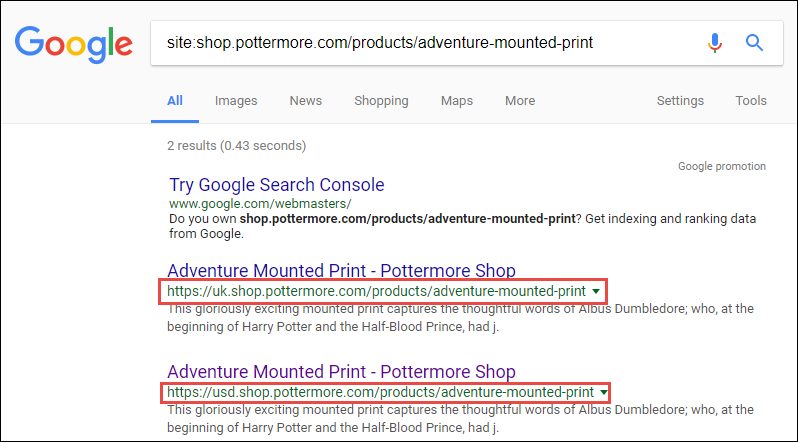
This is an example of a set of pages where you likely can’t just delete the content, but you can apply a fix (in this case proper use of hreflang tags) that will help improve the way Google understands and indexes your site across thousands of pages.
Incidentally, if you’re looking to determine whether a large list of duplicated URLs is actually indexed or not, you can run the URLs through URL Profiler to check their indexation status.
Digging a bit deeper, we can see that the reason these titles are duplicated isn’t just that there are multiple versions of a page targeted to different countries:
- https://usd.shop.pottermore.com/products/adventure-mounted-print
- https://usd.shop.pottermore.com/collections/mounted-prints/products/adventure-mounted-print
These two URLs, even in the U.S. shop, have the exact same content. Rather than having two paths through the site (one through products, the other through collections) lead to the same URL, the site is creating duplicated versions of products.
This is true for literally every piece of art on the Pottermore site:
- https://usd.shop.pottermore.com/collections/the-pottermore-art-collection/products/harry-potter-and-the-chamber-of-secrets-poster
- https://usd.shop.pottermore.com/products/harry-potter-and-the-chamber-of-secrets-poster
Here again we see that there’s an underlying issue impacting each of these product pages. Now that we’ve identified it, every time we see something similar in our reports we know the reason for the duplication (we’ll get to how to address it in a minute).
Scrolling down our list of URLs, we can quickly find another couple of common duplicate content culprits:
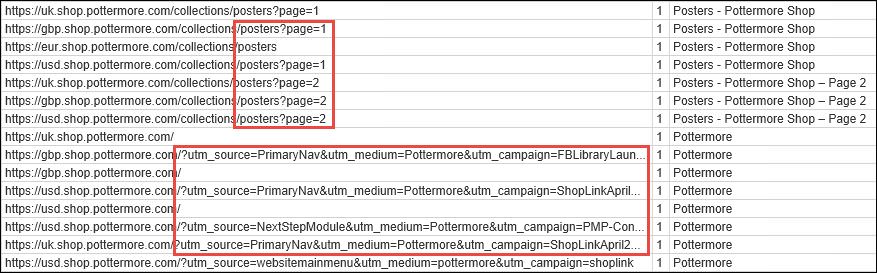
In this instance, Pottermore actually does have unique title tags for their paginated poster results, but generally you’ll often find that sites aren’t handling pagination correctly. Implementing rel previous and rel next and/or adding noindex follow tags to paginated results can help clean up what may be thousands of thin pages.
Additionally, we can see Google Analytics tracking parameters above. Parameters can be another area where you may have thousands of duplicated pages sneaking into the index.
You’ll take a similar approach with what you find in an analytics report. I don’t have access to the Google Analytics account for Pottermore, but we can imagine that I might have found that some pages like this…
https://www.pottermore.com/image/graveyard-at-night
…show up as both thin content within a Deep Crawl report, and also have low traffic and/or extremely high bounce rates. If that’s the case, again I’ll want to note it and add it as a potential “content type” that I may want to address in some way.
Next, I need to start to apply solutions to my list of problems.
Tools of the Trade: Your Options for Cleaning Up Indexation Issues
Now that I have a list of the URLs that could be causing me problems and I understand the root of those issues, I can start to go step-by-step and get the problem content out of the index. To do this, I have to understand the tools that are available to me.
Robots.txt
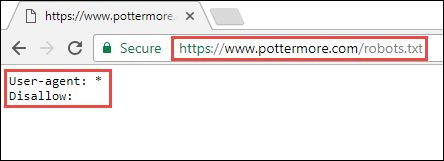
A common and well-known tool for dealing with indexation issues is a site’s robots.txt file. I find that this tool is frequently misunderstood, however.
An important note about disallowing a page or section of your site through robots: you are blocking Google from crawling this section of your site. If your pages are already in the index, adding a robots operative does not prohibit Google from keeping those pages in the index.
The benefit of this approach is that you’re conserving crawl budget by keeping Google from coming back to these pages. And if you have a new batch of pages or section of your site that’s not yet indexed, you can prevent those pages from being indexed.
The disadvantage is that Google can’t follow links on these blocked pages (if they link to other pages you’d want to discover), and again if they’re already in the index, disallowed pages won’t necessarily be removed.
Meta Noindex Tag
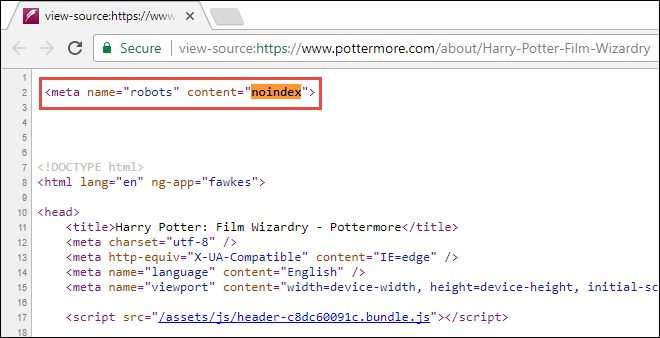
Conversely, by adding a meta noindex tag you can actually have your pages removed from Google’s index once those pages are crawled.
The pros and cons here are essentially the flip side of using the robots file: you have pages in the index removed and you’re able to have links within noindexed content be followed for discovery (assuming you include a meta follow tag as well), but you don’t stop Google from crawling your noindexed pages, and Google may not “come back” to remove your page if it’s a deeper, less important page or section of the site.
To help move along the removal of these pages from the index, you can use the URL removal tool detailed below, or you can submit to the index using Google Search Console’s fetch as Google tool.
Canonical Tag
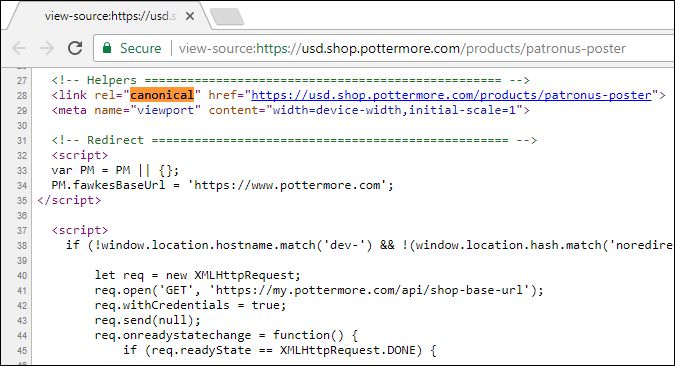
Generally, it’s always best to try to fix the root of a duplicate content problem, so redirecting pages, preventing your CMS from creating duplicated content, etc. are all preferable to just applying a canonical tag and moving on.
That said, properly adding a canonical tag can help indicate to Google which version of your page is actually the primary or “canonical” result that Google should return in search results.
Just make sure you don’t screw up the implementation!
Learn More: Beginner’s Guide to Properly Using Rel Tags To Improve Your Site’s Rankings
Remove URL Tool
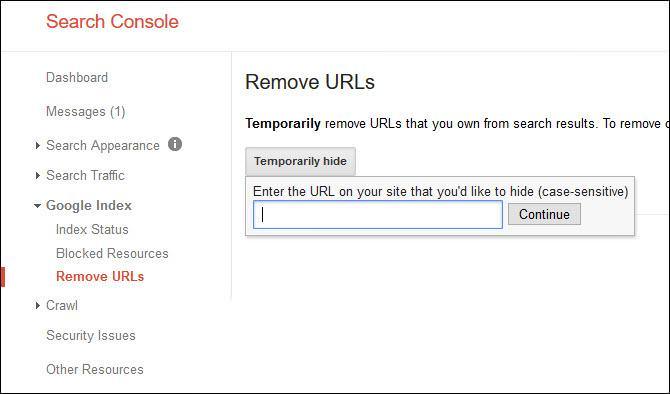
Pairing a robots operative with a noindex tag is pointless, but what if you really can’t get a developer to get access to add meta noindex tags to a section of your site?
One alternative is to couple adding a robots operative with submitting your URL to Google Search Console for removal. There’s even a cool, free Chrome extension to help with bulk removal.
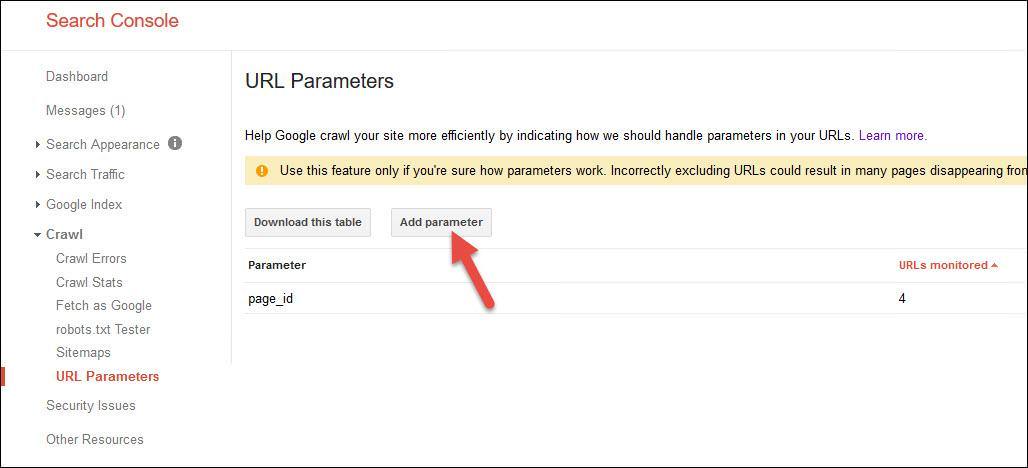
Parameter Handling in Google Search Console
Additionally, if you’re tracking parameters or faceted navigation and want to deal with some parameters that are being indexed that shouldn’t, you can address those from the URL Parameters section of Google Search Console:
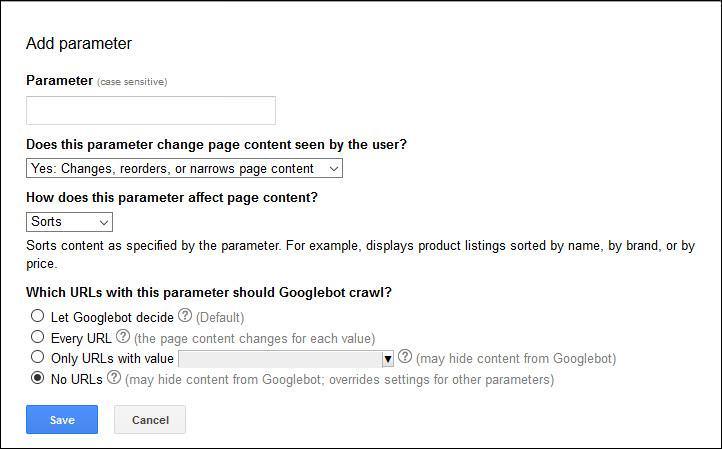
Just be careful to properly classify your parameters within the tool:
XML Sitemaps
Additionally, making sure that your XML sitemap is up to date and isn’t generating errors can help Google crawl and understand your site – and given the new Search Console indexation reports mentioned above, the XML sitemap will become even more valuable.
Deleting or Redirecting Pages
Say we have ~100 older, lower-quality, 150-word blog posts we wrote when we started our company blog. They may very well be indexed, but are not getting any traffic, have never been shared, and have never been linked to by external sites. We may want to noindex these, but we could also simply delete them and submit the URLs for removal.
Similarly, if we have a page that is very low-quality and not visited by users often (or even duplicated) but has some stray links from external sources, it’s a good idea to 301 redirect that page to the most relevant page (or its duplicate).
Thickening & Promoting a Page
After you work through the pure duplicates, tracking parameters, and lower-value pages you want to delete, you may have some areas where you have pages that are actually of value to users and that you’d like to keep in the index (and perhaps improve the performance of in terms of traffic and engagement metrics like time on site and bounce rate).
In these instances, you can work on thickening up your existing pages, promoting them, and addressing poor bounce rates rather than simply removing them from the index.
Wrapping Up
If you’ve discovered that many of your web pages have been getting indexed as a result of low-quality, duplicated content in addition to poor link and engagement metrics, I hope that this article has helped you identify whether you do, indeed, have an issue with duplicate or thin content and indexation, and if so, how to determine which pages are causing the problem and then how to clean it up.

