Google BERT stands for Bidirectional Encoder Representations from Transformers and is an update to the core search algorithm aimed at improving the language understanding capabilities of Google.
BERT is one of the biggest Google core updates that Google has made since RankBrain in 2015 and has proven successful in comprehending the intent of the searcher behind a search query.
How Does Google BERT Work?
Let’s understand what BERT can do with the help of an example query:

Here, the intent of the searcher is to find out whether any family member of a patient can pick up a prescription on their behalf.
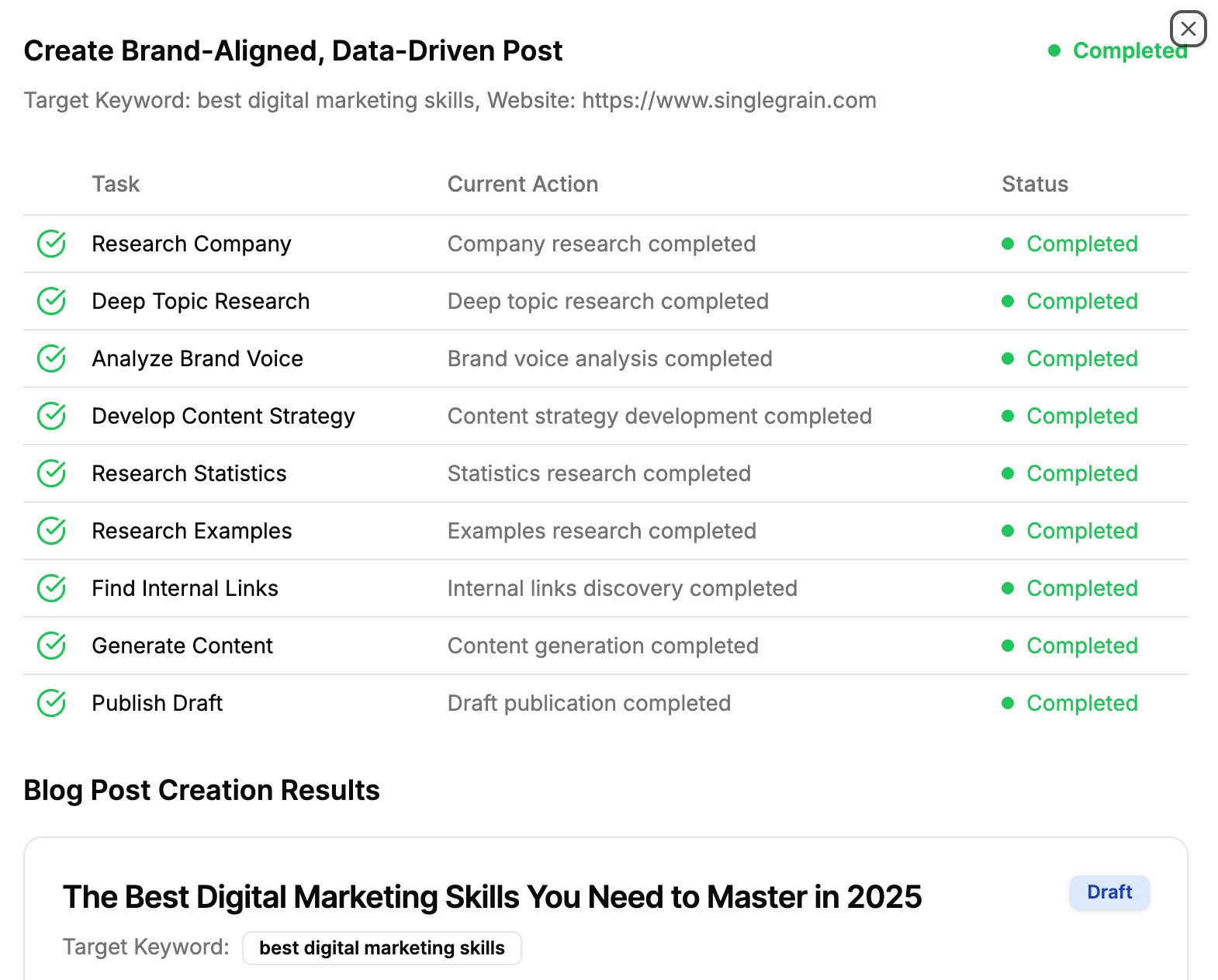
Here is what Google returned before BERT:
As you can see, Google has returned an unsatisfactory search result because it was unable to process the meaning of the word “someone” in the query.
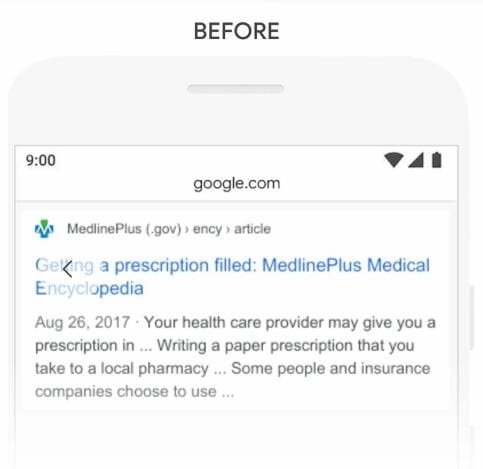
Here is what Google returned after BERT systems were integrated into the core algorithm:
This search result accurately answers the searcher’s question. Google has now understood the meaning of the word “someone” in the correct context after processing the entire query.
Instead of processing one word at a time and not assigning substantial weight to words like “someone” in a specific context, BERT helps Google process each and every word in the query and assigns a token to them. This results in much more accurate search results.
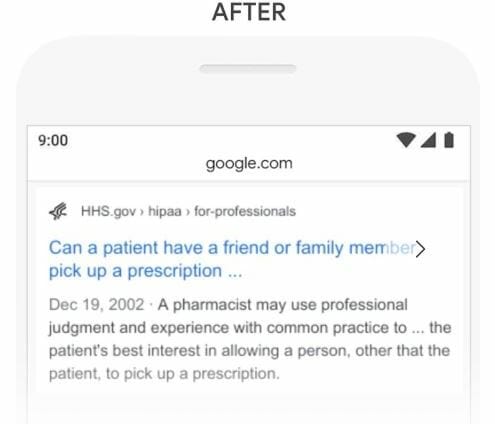
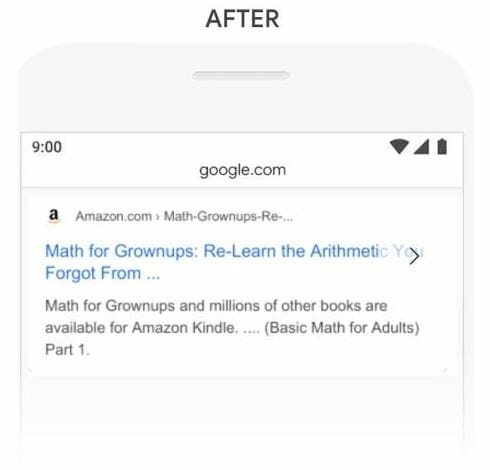
In another example, the query is “math practice book for adults” where the searcher is looking to buy math books for adults:

Before BERT, Google returned results suggesting books for grades 6-8, which is incorrect. Google provided this answer because the description contains the phrase “young adult,” but in our context, “young adult” is irrelevant to the question:
After BERT, Google is able to correctly discern the difference between “young adult” and “adult” and excludes results with out-of-context matches:
Dive Deeper:
- How to Understand Searcher Intent and Use It to Boost SEO Rankings
- How to Prepare Your Site for the New Google Page Experience Update
What Is Google NLP and How Does It Work?
NLP stands for Natural Language Processing, which is a subset of artificial intelligence and consists of machine learning and linguistics (study of language). It’s what makes communication between computers and humans in natural-sounding language possible.
NLP is the technology behind such popular language applications as:
- Google Translate
- Microsoft Word
- Grammarly
- OK Google, Siri, Cortana and Alexa
NLP is the framework that powers Google BERT. The Google natural language API consists of the following five services.
1) Syntax Analysis
Google breaks down a query into individual words and extracts linguistic information for each of them.
For example, the query “who is the father of science?” is broken down via syntax analysis into individual parts such as:
- Who tag = pronoun
- Is tag (singular present number) = singular
- The tag = determiner
- Father tag (noun number) = singular
- Of tag = preposition
- Science tag = noun
2) Sentiment Analysis
Google’s sentiment analysis system assigns an emotional score to the query. Here are some examples of sentiment analysis:

Please note: The above values and examples are all taken randomly. This is done to make you understand the concept of sentiment analysis done by Google. The actual algorithm that Google uses is different and confidential.
3) Entity Analysis
In this process, Google picks up “entities” from a query and generally uses Wikipedia as a database to find the entities in the query.
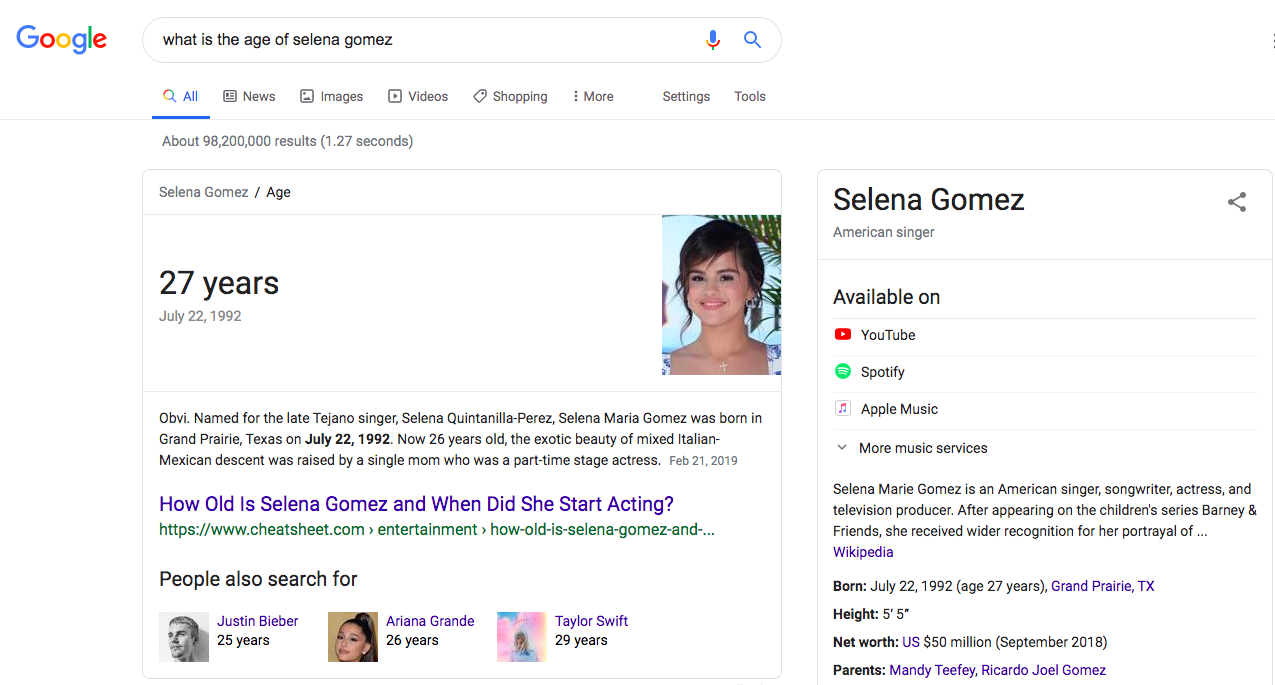
For example, in the query “what is the age of selena gomez?”, Google detects “Selena Gomez” as the entity and returns a direct answer to the searcher from Wikipedia:
4) Entity Sentiment Analysis
Google goes a step further and identifies the sentiment in the overall document containing the entities. While processing web pages, Google assigns a sentiment score to each of the entities depending on how they are used in the document. The scoring is similar to the scoring done during sentiment analysis.
5) Text Classification
Imagine having a large database of categories and subcategories like DMOZ (a multilingual open-content directory of World Wide Web links). When DMOZ was active, it classified a website into categories and subcategories and even more subcategories.
This is what text classification does. Google matches the closest subcategory of web pages depending on the query entered by the user.
For example, for a query like “design of a butterfly,” Google might identify different subcategories like “modern art,” “digital art,” “artistic design,” “illustration,” “architecture,” etc., and then choose the closest matching sub category.
In the words of Google:
“One of the biggest challenges in natural language processing (NLP) is the shortage of training data. Because NLP is a diversified field with many distinct tasks, most task-specific datasets contain only a few thousand or a few hundred thousand human-labeled training examples.”
To solve the problem of a shortage of training data, Google went a step further and designed Google AutoML Natural Language that allows users to create customized machine learning models. Google’s BERT model is an extension of the Google AutoML Natural Language.
Please note: The Google BERT model understands the context of a webpage and presents the best documents to the searcher. Don’t think of BERT as a method to refine search queries; rather, it is also a way of understanding the context of the text contained in the web pages.
Dive Deeper: The Effects of Natural Language Processing (NLP) on Digital Marketing

What Is BERT NLP?
BERT is an open-source model and is an extension of the Google AutoML Natural Language as explained above. BERT is the method that will be used to optimize NLP for years to come.
As Google suggests:
“We open sourced a new technique for NLP pre-training called Bidirectional Encoder Representations from Transformers, or BERT. With this release, anyone in the world can train their own state-of-the-art question answering system (or a variety of other models) in about 30 minutes on a single Cloud TPU, or in a few hours using a single GPU.”
BERT represents the new era of NLP and probably the best that has been created so far.
Thang Luong, senior research scientist at Google Brain, tweeted this prior to the launch of BERT:
A new era of NLP has just begun a few days ago: large pretraining models (Transformer 24 layers, 1024 dim, 16 heads) + massive compute is all you need. BERT from @GoogleAI: SOTA results on everything https://t.co/YQaY7baIQg. Results on SQuAD are just mind-blowing. Fun time ahead! pic.twitter.com/1phsCZpqWR
— Thang Luong (@lmthang) October 12, 2018
BERT Helps Google Process Conversational Queries
The Google BERT update (a component of Natural Language Processing) is aimed at processing conversational queries and, as the search engine giant says:
“Particularly for longer, more conversational queries, or searches where prepositions like ‘for’ and ‘to’ matter a lot to the meaning, Search will be able to understand the context of the words in your query. You can search in a way that feels natural for you.”
Pre-trained language representation strategies such as ‘feature-based’ and ‘fine-tuning’ have shown to improve many natural language processing tasks:
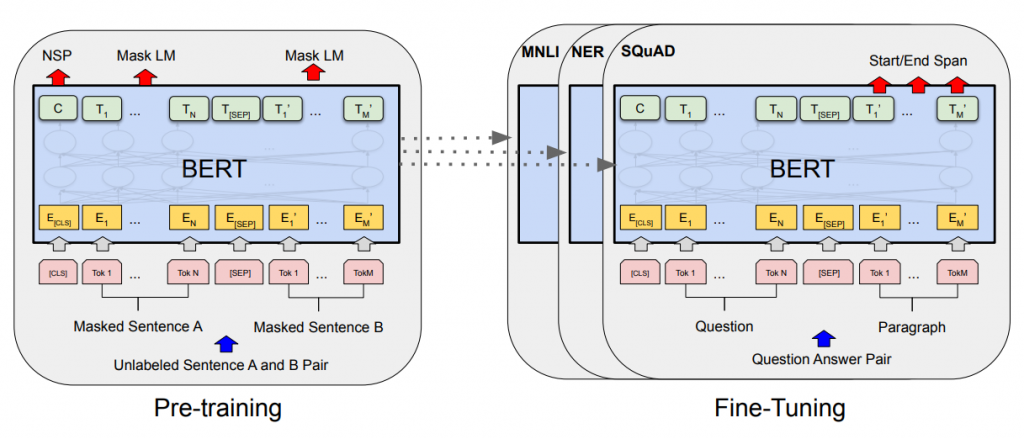
BERT improves the “fine-tuning” language representation strategy. It alleviates the previously used unidirectionality constraint by using a newer “masked language model” (MLM) that randomly masks some of the words from the sentence and predicts the original vocabulary of words based only on its context.
As suggested in this research paper by Google entitled “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding”:
“BERT is the first fine-tuning-based representation model that achieves state-of-the-art performance on a large suite of sentence-level and token-level tasks, outperforming many task-specific architectures…. [It] is conceptually simple and empirically powerful. It obtains new state-of-the-art results on eleven natural language processing tasks, including pushing the GLUE score to 80.5% (7.7% point absolute improvement), MultiNLI accuracy to 86.7% (4.6% absolute improvement), SQuAD v1.1 question answering Test F1 to 93.2 (1.5 point absolute improvement) and SQuAD v2.0 Test F1 to 83.1).”
That’s a lot of technical language, but the essence is this:
BERT is a powerful upgrade to the existing NLP algorithms that Google currently uses to process search queries in order to present the best results possible to the user. Share on XBERT runs on 11 NLP tasks and improves the accuracy score of each of them thereby resulting in accurate search results.
Dive Deeper:
- VSEO: How Voice Search and Conversational AI Are Changing SEO
- 12 Ways to Use Machine Learning in Digital Marketing
- 10 Easy Ways to Get Started with Marketing AI (Artificial Intelligence)
Transformers: The Real Power Behind Google BERT
The core of the BERT functioning lies in a Transformer, which is a novel neural network architecture for language understanding. It outperforms all other previous processes of language modeling and machine translation.
Google can now process words in a query using Transformers and as per Pandu Nayak, Google Fellow and Vice President of Search:
“[Transformers are] models that process words in relation to all the other words in a sentence, rather than one-by-one in order. BERT models can therefore consider the full context of a word by looking at the words that come before and after it — particularly useful for understanding the intent behind search queries.”
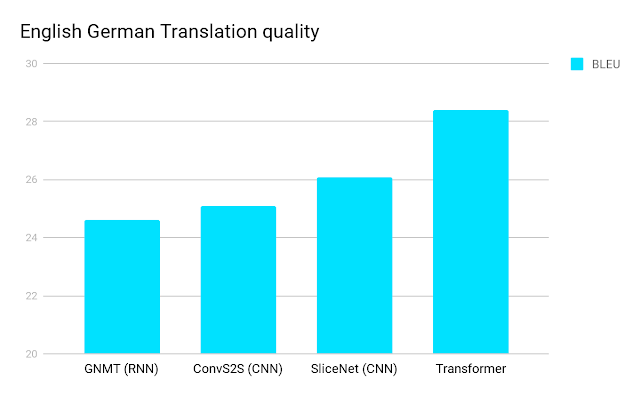
In a research paper entitled “Attention Is all You Need,” it is proven that transformers outperform both recurrent and convolutional models on academic English-to-German and English-to-French translation benchmarks:
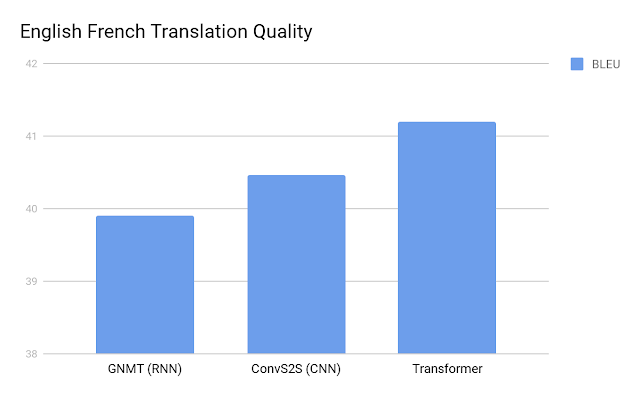
BERT Is a Way to Understand Relationships Between Sentences
The BERT model is aimed at understanding the relationships between sentences by pre-training on a very simple task generated using any text corpus (a collection of written material in machine-readable form, assembled for the purpose of linguistic research).
As suggested by Google, given two sentences — A and B — is B the actual next sentence that comes after A in the corpus, or just a random sentence? For example:
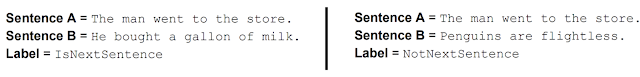
BERT adds an additional layer of artificial brain to Google’s architecture and is thus able to identify the relationship between sentences. It is now trained to think like a human and understands both the meaning and relationship between words in a sentence or a combination of sentences.
Dive Deeper: How Machine Learning Is Transforming Content Marketing
Google BERT FAQ
Here are some of the most commonly asked questions about BERT (Bidirectional Encoder Representations from Transformers).
When Did BERT Roll Out?
BERT rolled out on October 24, 2019 as confirmed by Pandu Nayak (VP, Google Search) in this blog post. This roll out was for English language queries only. However, the roll out is still in progress for other languages like Korean, Hindi and Portuguese.
What Effect Does Google BERT Have on My Website?
Google has applied BERT to both ranking and featured snippets in search. It impacts one in ten searches in the U.S. in English. Hence, if your website is in English and you are targeting English-language queries, then BERT will certainly affect the organic presence of your website.
BERT affects longer, more conversational queries where the context of the words in the query are hard to understand. If you are acquiring organic traffic to your website via long-tail searches, you need to keep a closer watch on them. Any changes in traffic from long-tail keywords might be due to the BERT algorithm.
I suppose all websites have a certain percentage of traffic that is acquired via long-tail searches, so this traffic might be affected by the BERT update. However, BERT won’t affect your rankings for shorter and more important keywords.
(Please note: Changes in organic traffic can be caused for a variety of reasons and BERT is just one such factor. A comprehensive content audit is required to identify the real reasons behind the decline in organic traffic. Don’t just assume that a change in organic traffic is only because of BERT.)
Keep an eye on your Google Analytics and break down the percentage of organic traffic via pages. If traffic to certain pages has gone down after the third week of October, then that those pages might be affected by BERT.
All you need to do is to ensure that your page accurately matches the search intent of the keywords you are looking to rank for. If you do that right, your website’s organic traffic will remain safe from the effects of BERT.
Dive Deeper: Why You Should Use Long-Tail Keywords in Your SEO Campaign
Is BERT an Extension of RankBrain?
No. BERT and RankBrain are different. Google applies a combination of algorithms to understand the context of a query. For some queries, RankBrain might be applied while for others BERT would be given a priority. There might be some searches where both RankBrain and BERT would be applied together to present the best results to the user.
Is BERT a Language Model?
BERT is a method of pre-training language representations. Under BERT, a general purpose language model is used on a large text corpus (like the Knowledge Graph) to find answers to the questions of the user.
How Exactly Does BERT Work?
BERT is all about understanding the intent behind the search. By applying BERT, Google is able to understand the relationship between words in a query and present the closest matching result to the searcher. BERT’s core innovation lies in the application of a transformer, which is a popular attention model to language modeling.
Before BERT, Google looked at the sequence of words in the query either from left to right or right to left.
After BERT was applied, Google has trained its systems to look bidirectionally at the query. This means Google can now look at the query both ways (from the right or left in a single processing). Here’s an example of bidirectional query processing:
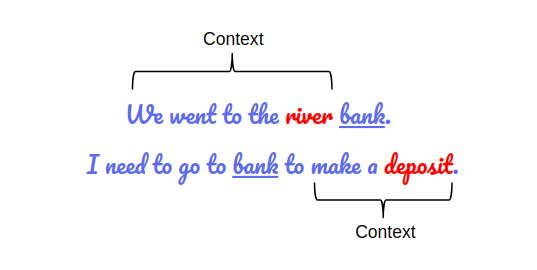
In the example above, the context of the word “bank” is different in both sentences. In the first sentence it refers to a river bank, while in the second one it refers to a financial institution. In order to understand the real meaning of the word “bank” here, Google needs to process the context of the words before the word “bank” in the first query and after the word “bank” in the second query. This is what bidirectional query processing is. Google can process a query both ways depending on the context.
BERT gives Google a deeper sense of language context and bidirectional flow than single-direction language models. This research paper discusses a novel technique called Masked LM (MLM), which is the core of BERT. The Masked LM allows bidirectional training in models, which had been impossible until now.
I would recommend that you watch the video below to get a better understanding of how BERT works. This video is presented by Danny Luo, machine learning engineer at Dessa:
Does BERT Apply to Other Language Queries (Apart from English)?
Yes, it applies to other languages like Hindi, Korean, Portuguese and others. Google has applied BERT to twelve different countries but the rollout is completed for English searches only. In the coming months, BERT will continue to impact other language queries.
Does BERT Process “Stop” Words?
Certainly! Previously, Google would remove all the “stop” words from a query before processing it, but now it carefully considers all the stop words for understanding the context of the query.
Stop words are short function words that used to be ignored by the search engines because they didn’t add any semantic value to the search. Some examples of stop words are the, on, at, which, that, etc.
But with updates like RankBrain and BERT, Google has gone a step further in understanding humans in the language that they are most comfortable with, not that machines are most comfortable with. Google’s motto of becoming the most accurate answer engine is closer than ever with the launch of BERT.
How Can I Optimize for BERT?
The only thing you can do is to ensure that the content on your pages matches the intent of the searcher. There is nothing special you can do to optimize for BERT. This is what Danny Sullivan, Google’s public search liaison, tweeted:
There’s nothing to optimize for with BERT, nor anything for anyone to be rethinking. The fundamentals of us seeking to reward great content remain unchanged.
— Danny Sullivan (@dannysullivan) October 28, 2019
Google has always put special emphasis on GREAT content — and BERT is an extension of that. Prepare great content for your audience and your site will do well in search.
Here are some ways to prepare GREAT content:
- Write easy-to-read text. You can measure the readability scores of your content by using tools like Readable. This tool also calculates the Flesch-Kincaid readability scores. You must aim for a score of 8.
- Create original and error-free content.
- Organize your topic clearly.
- Add proper headings, subheadings and divide the content into proper paragraphs.
- Keep the content accessible and actionable.
- Avoid Zombie content, as it can hamper the quality of your web page.
- Get rid of duplicate content and keep your content fresh.
- Avoid cloaking in all forms.
- Display author information clearly on your site because expertise is a great way to improve the trust score of your website.
- Use links wisely and optimize your images.
- Keep your site mobile-friendly.
- Analyze user behavior on your site and continually take actions to improve your content.
Dive Deeper:
- 4 Ways to Signal to Google that You’re an Expert Content Creator
- 9 Effective SEO Techniques to Drive Organic Traffic
- Absolutely Everything You Need to Know About 10x Content
- 7 SEO Copywriting Tips to Increase Your Rankings in 2019
How Is BERT Different from Previous Models?
BERT is a pre-training method that is applied on vast sets of data to refine the search query. The below figure shows the comparison of the BERT model with the earlier pre-training architecture models:
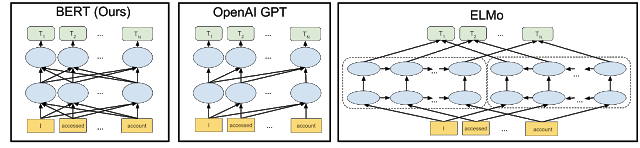
The arrows represent the flow of information from one layer to the other. The green boxes at the top represent the final output from every input word. As you can see from the above figure, BERT is deeply bidirectional while OpenAI GPT is unidirectional and ELMo is shallowly bidirectional.
Is BERT 100% Accurate?
No, BERT is not 100% accurate. For example, if you search for “what state is south of Nebraska,” BERT will guess that it is “South Nebraska” which is not accurate.
Google is still learning and Rankbrain and BERT are examples of algorithms that are enabling Google to think like a human. We can expect newer and more improved versions of this algorithm soon.
Dive Deeper: How to Write Content for People and Optimize It for Google
Learn More: How SEO Will Change in 2023…and You’re Not Going to Like It
Final Thoughts
Google BERT is one of the biggest updates that Google has launched in recent years. It has given users the power to search in natural language instead of using unnatural keywords to get the best results. Google is getting rid of “keywordese” and making search more human.
As an SEO or a content marketer, there is nothing special you can do to optimize for BERT. If you have been following all the content guidelines suggested by Google and writing your content for the user, then BERT won’t disappoint you. It is only aimed at returning the best results to searchers after accurately understanding their intent.