How AI Models Handle Edge-Case Scenarios in How-To Content
Edge-case LLM content represents the breaking point for most AI assistants, where the system encounters a scenario that defies its standard training patterns. While generic queries yield confident answers, reliability often drops when users present unusual setups, rare constraints, or jurisdiction-specific rules. This is why 52% of social users are concerned about brands posting AI-generated content without disclosure.
When a model has only seen the “happy path” (the ideal, error-free scenario) in its training data, it tends to improvise in these gray areas. It produces instructions that look confident but fall apart under scrutiny. For organizations shipping AI assistants or AI-written documentation, these failures erode trust quickly. You need to understand how models behave in these margins to fix them.
In how-to content, the impact of a single wrong step or missing caveat ranges from mild frustration to compliance violations. Fortunately, you can systematically design your content and AI workflows so that exceptions and constraints are handled explicitly rather than left to guesswork. This approach improves user trust and makes citations based on AI-generated answers far more accurate.
TABLE OF CONTENTS:
Why Edge-Case LLM Content Matters in How-To Guides
An LLM “edge case” is a query where the model cannot safely rely on the most common pattern in its training data. This might be a rare combination of conditions, a nonstandard configuration, or an instruction that blends multiple domains. In how-to content, these appear as specific user questions, such as “Does this still apply if I’m on a legacy system?” or “What about regulations in my specific country?”
Step-by-step instructions differ from generic blog posts because users act on them immediately. They follow the steps, cite the answer in their work, or forward it to a colleague. If the model omits an important exception or silently assumes the wrong context, the resulting error feels like a breach of trust.
This makes edge-case handling central to any serious AI content strategy. 63% of Gen Z and 49% of millennials say product reviews and recommendations are the most influential factors in their purchasing decisions. Since many “reviews” are effectively how-to snippets, any AI involvement propagates quickly and shapes decisions far beyond the original context.
Teams designing AI experiences must anticipate these edge-case categories:
-
Safety-sensitive steps where misuse could cause harm.
-
Jurisdictional differences that change what is allowed (e.g., GDPR vs. CCPA).
-
Rare user states that requires a different path through the steps.
-
Ambiguous instructions where multiple interpretations exist.
-
Multi-system workflows where hidden dependencies can break the process.

How AI Models Currently Handle Edge-Case LLM Content
General-purpose LLMs act as pattern machines. They predict the next token based on what they have seen most often in similar contexts. This works well for straightforward how-to queries, but becomes fragile when the question falls between patterns. Faced with a rare combination of conditions, the model often blends nearby examples and fills gaps with plausible-sounding but unverified steps.
Many failures begin with unclear questions. Simple clarifications, like asking which operating system the user is running, can often turn a potential edge case into a routine one. Production systems must be designed to ask these clarifying questions rather than assuming the answer.
Retrieval-augmented generation (RAG) adds a layer of safety by pulling relevant chunks of documentation. However, if exceptions live in dense footnotes or scattered support articles, the model may retrieve the right documents yet still miss the constraint. By 2027, organizations will use small, task-specific AI models three times more often than general-purpose LLMs. Narrower models can be fine-tuned with explicit caveats and domain constraints, which improves behavior on known edge-case patterns.
You must also consider how models weigh different parts of a page. A brief warning box or footnote often carries more real-world importance than the long explanatory text around it. Unless your system explicitly surfaces those “thin but critical” elements, models will easily overlook them when generating answers.
Designing Edge-Case LLM Content for Trust and Accuracy
Once you understand model behavior, you can design your how-to pages so that exceptions are impossible for the model to ignore. This involves both information design (how you structure content) and prompting (how you instruct models to treat that structure).
Information Design Principles
LLMs pay close attention to headings and section boundaries. Clear labels such as Prerequisites, Limitations, Exceptions, and Not Covered help both humans and models distinguish standard instructions from special conditions. You should keep the main happy-path steps separate from exception flows instead of weaving them into long narrative paragraphs.
Adding structured metadata strengthens these design choices. Schema markup can signal relationships like “only applicable if” or “excluded in region,” which a downstream system can respect when assembling an answer. For regulated domains, pages that spell out boundaries (such as what is and is not covered) tend to produce safer AI responses.
Prompt Patterns for Trustworthy Content
Content structure requires prompts that force the model to surface edge conditions. Instead of asking a model to “Explain how to do X,” use multi-part instructions that explicitly call for assumptions and exceptions.
Try a prompt pattern like this:
-
“Explain the steps to configure feature X.”
-
“First, list all assumptions you are making.”
-
“Then provide step-by-step instructions.”
-
“Finally, add a labeled ‘Exceptions and limitations’ section.”
This puts the burden on the model to look for caveats in your documentation rather than defaulting to a one-size-fits-all answer.
Content Governance and Disclosure
Even with strong prompts, human oversight is necessary. Readers need to know when an answer was AI-assisted and how it was checked. Clear banners or notes explaining AI involvement go a long way toward calibrated trust.
If you need a partner who can connect those dots and design answer-engine-ready content, Single Grain can help you architect your AEO end-to-end. Get a FREE consultation.
Framework to Manage Edge Cases in How-To Systems
Handling edge-case behavior is a continuous lifecycle that combines logging, analysis, design, and monitoring. Treating edge-case LLM content as a living system helps you progressively reduce risk.
1. Discovery
Capture where your AI system is already failing. Look at user feedback flags, manual reviews of low-confidence answers, and logs of queries that lead to refusals. Build a backlog of real-world edge cases rather than guessing.
2. Classification
Group edge cases by risk level and domain. High-risk categories, like anything involving safety or finance, should be addressed first. You can fix lower-risk areas, such as formatting quirks, in batches later.
3. Solution Design
Choose the right intervention. Some problems call for content rewrites; others need prompt changes or specialized models. Reliable systems combine several of these layers so that if one misses a caveat, another catches it.
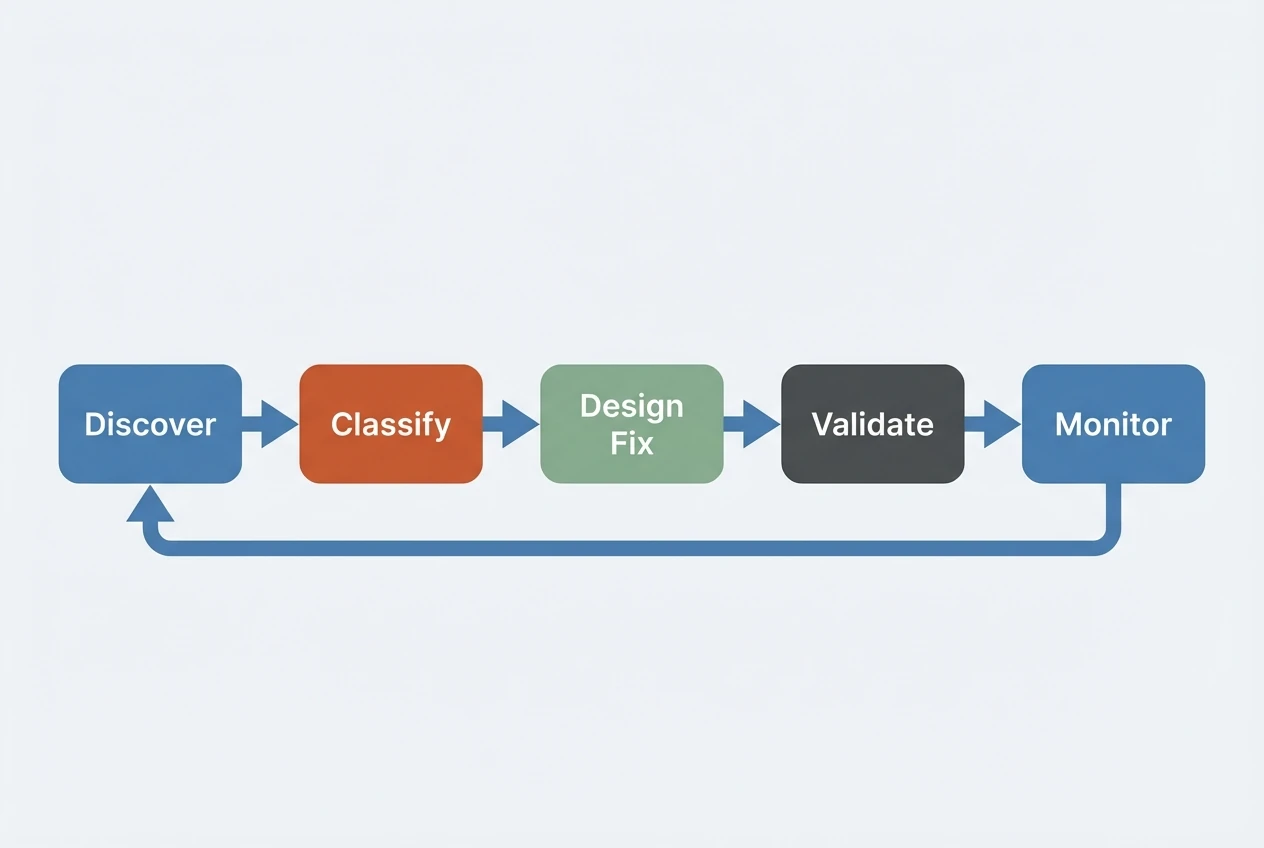
4. Validation and Monitoring
Use targeted test sets for known edge-case queries. Monitor live metrics, including refusal rates and escalation volume. When new failures appear, feed them back into the discovery stage.
| Edge-case type | Example in how-to content | Recommended mitigation |
| Factual / citation-sensitive | Tax limits, regulatory thresholds, or version-specific features | Ground answers via RAG on authoritative sources; require explicit citations with dates |
| Safety / policy-sensitive | Medical, legal, financial, or self-harm-related instructions | Use safety classifiers; default to refusal or human expert escalation |
| Ambiguous steps | Instructions that differ by platform, region, or user role | Prompt models to ask clarifying questions or branch answers by condition |
| Domain-specific configs | Nonstandard API limits, custom deployments, legacy systems | Introduce domain-tuned models and curated examples; mark unsupported scenarios clearly |
Turning Edge-Case LLM Content Into an Advantage
Edge cases are situations in which AI systems either build durable trust or lose it in a single interaction. Deliberately designing your documentation, prompts, and governance workflows around exceptions will turn a traditional LLM weakness into a strength. Users learn that when your AI does not know the answer or when conditions fall outside safe bounds, it clearly says so.
Teams that invest in edge-case LLM content now are building the backbone of trustworthy answer engines. Instead of hoping generic models get rare scenarios right, you are encoding domain knowledge and risk rules into every layer of your stack.
If you are ready to treat edge cases as a core feature of your strategy, Single Grain can help you design the technical architecture and content systems to support it. From SEO strategy to guardrails and human-in-the-loop workflows, we have the expertise you need. Get a FREE consultation.
Related Video

Frequently Asked Questions
-
How can we measure the ROI of improving edge-case handling?
Track metrics like support ticket volume for complex issues and time-to-resolution. Pair these with user satisfaction scores focused specifically on your AI experience to attribute gains to better edge-case coverage.
-
Who should own the strategy for edge-case LLM content?
Ownership typically sits at the intersection of product, content, and risk. The most effective setups define a cross-functional council that approves standards and signs off on high-risk flows.
-
How do we involve subject-matter experts (SMEs) efficiently?
Use SMEs to define patterns and guardrails rather than reviewing every single answer. Centralize their feedback into reusable templates that content teams can apply at scale.
-
What is a realistic first step for smaller teams?
Audit your top how-to pages to identify recurring edge cases. Rewrite those pages with clearer prerequisites and exception sections, then update your prompts to force the AI to surface those elements.
-
How should we evaluate third-party AI vendors?
Give vendors a test suite of your real, high-risk edge-case queries. Require them to demonstrate answer behavior, refusals, and escalation paths before you sign a contract.

